De zomerstop. Voor de voetballers was het een welkome rustperiode na een lang en ongetwijfeld hectisch seizoen, maar voor de (aspirant-)voetbalstatisticus brak juist een tijd aan van hard werken aan nieuwe modellen om het komende seizoen beter in kaart te kunnen brengen. In een zoektocht naar inspiratie voor zo’n voorspellend model van de Eredivisie stuitte ik op een wetenschappelijk artikel waarin het Pi-ratingsysteem wordt geïntroduceerd. Het model bleek de Premier League beter te voorspellen dan de bookies over de seizoenen 2007/2008 tot en met 2011/2012 – en bovenal: het was redelijk simpel te begrijpen én toe te passen. Tijd om geld te verdienen!
Pi-Rating
De heren Anthony Constantinou en Norman Eaton hadden het lumineuze idee om een voorspellend model te maken wat begrijpelijk was en toepasbaar binnen alle sporten waarbij de einduitslag een goede indicator is van de prestatie. De Pi-rating was geboren. De ‘Pi’ in Pi-rating staat voor Probabilistic Intelligence. Vrij vertaald: het model berekent op basis van historische resultaten kansen op bepaalde uitslagen. De bedenkers van het Pi-rating model beredeneerden dat er met minimaal drie factoren rekening gehouden moet worden als je een accurate voorspelling in het voetbal wil maken.
- Thuisvoordeel; er moeten verschillende Pi-ratings voor uit- en thuiswedstrijden komen.
- Alle wedstrijden uit het verleden tellen mee om de Pi-rating van een team te bepalen, maar de laatste wedstrijden tellen veel zwaarder mee dan wedstrijden van een paar maanden geleden.
- Een overwinning is voor het team belangrijker dan het goalverschil vergroten. Met andere woorden: een 5-0 overwinning telt wel zwaarder mee dan een 1-0, maar niet vijf keer zo veel.
De enige data die dit model nodig heeft, is het goalverschil, ofwel Goal Difference (GD). Goal Difference is het verschil in goals tussen de thuis- en uitspelende ploeg. Bij een 4-1 wedstrijd is de GD dus 3. Deze eenvoud maakt het ook mogelijk om het Pi-ratingmodel toe te passen in de 5e klasse reserve om een wedstrijd van je lokale FC tegen de rivaal uit het volgende dorp te voorspellen. Na het invoeren van veel uitslagen uit het verleden van de betreffende competitie krijgt elk team twee cijfers die de kwaliteit van het team uit en thuis weerspiegelen: de Pi-rating.
Het Pi-ratingmodel is ook toe te passen in de 5e klasse reserve om een wedstrijd van je lokale FC tegen de rivaal uit het volgende dorp te voorspellen.
De Pi-rating is positief voor sterkere teams en negatief voor teams die onder het gemiddelde presteren; het gemiddelde van alle teams is dus 0. Op basis van de Pi-ratings van beide teams wordt voorafgaand aan een wedstrijd een verwacht goalverschil – de Expected Goal Difference of ExpGD – berekend, en na de wedstrijd worden de Pi-ratings geüpdatet door te kijken of er is voldaan aan de verwachting. (Voor de stat-liefhebbers die niet vies zijn van logaritmes en wiskundige vergelijkingen: zie de volledige uitleg van het model in het originele artikel van de heren Constantinou en Eaton hier.
Pi-rating in de Eredivisie
Voor dit project zijn de uitslagen van alle wedstrijden sinds de start van seizoen 2010/2011 gebruikt. Misschien weet u het nog wel: dat was het rampjaar voor Feyenoord, met onder andere de beruchte 10-0 nederlaag uit tegen PSV en een uiteindelijke 10e plaats op de ranglijst. In figuur 1 is de ontwikkeling van de Pi-rating van de traditionele topdrie weergegeven.
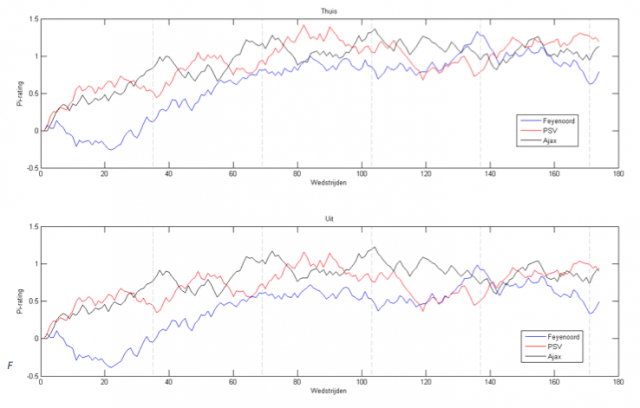
Alle clubs beginnen op nul. Waar bij PSV en Ajax direct een stijgende lijn te zien is, is de Pi-rating van Feyenoord een groot deel van seizoen 2010/11 zelfs onder het gemiddelde van de Eredivisie. Sinds dat seizoen is Feyenoord weer mee gaan draaien met PSV en Ajax, en de Rotterdammers waren aan het eind van het seizoen 2013/2014 zelf hoger gewaardeerd dan de ploegen uit Eindhoven en Amsterdam. Ook het verval van Feyenoord in het laatste deel van vorig seizoen is duidelijk te zien.
In de lijn van Ajax is de periodieke herfstdip uit de seizoenen 2011/2012 (rond wedstrijd 40), 2012/2013 (rond wedstrijd 75) en 2013/’14 (rond wedstrijd 105) goed zichtbaar. Na de winsterstop van afgelopen seizoen hadden de hoofdstedelingen ook een dip, die goed te zien rond wedstrijd 155. In de ontwikkeling van de Pi-rating van PSV is één grote vormdip te herkennen, voor de winterstop in het seizoen 2013/2014. In die periode werd er in negen wedstrijden zes keer verloren – onder andere van Roda JC en NAC, die een matige Pi-rating hadden – en slechts één keer gewonnen.
NEC kende een lange tijd een bestaan in de grijze middenmoot van de Eredivisie, maar aan het einde van het seizoen 2012/2013 kelderde de Pi-rating van de Nijmegenaren in slechts vijftien wedstrijden naar het niveau van een degradatieklant. En inderdaad: de degradatie was een jaar later een feit.
Bij Vitesse valt een plotselinge stijging aan het begin van seizoen 2012/2013 op. In dit seizoen stond Fred Rutten aan het roer in Arnhem. Was het de hand van de coach of was het de samenwerking met Chelsea die dat jaar voor het eerst goed op gang kwam? Hoe dan ook; sinds dat jaar heeft Peter Bosz de stijgende lijn met wat ups en downs vastgehouden.
Na drie wedstrijden in het seizoen 2015/2016 is de ranglijst op basis van gemiddelde Pi-rating als volgt. PSV en Ajax staan met groot verschil bovenaan, en niet Feyenoord maar Vitesse completeert het trio. De Graafschap staat eenzaam laatste.
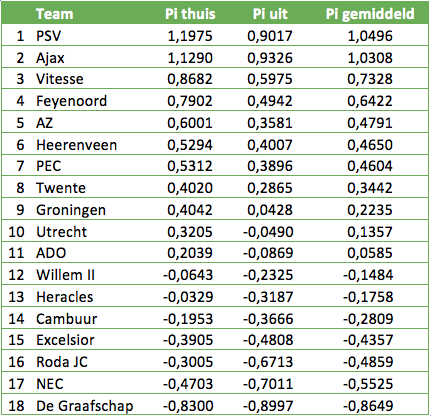
Bij Roda JC is het grootste verschil tussen thuis- en uit-rating te vinden. Bij de Graafschap is dit verschil het kleinst. Dit zou ook kunnen komen door het feit dat De Graafschap in de periode van 2010/2011 tot 2015/2016 slechts 72 wedstrijden in de Eredivisie speelde en dat de Pi-rating nog niet volledig gestabiliseerd is. Van de clubs die er alle seizoenen bij waren, heeft FC Utrecht het grootste thuisvoordeel en FC Twente het kleinste.
Wedstrijden voorspellen
Met de Pi-rating kunnen we voor iedere wedstrijd het verwachte verschil in doelpunten tussen de beide teams berekenen, maar het model heeft het natuurlijk niet altijd bij het rechte eind. Als er een ExpGD van +1.2 voorspeld wordt, is de kans groot dat de thuisploeg gaat winnen, maar er is natuurlijk altijd een kans dat de uitploeg verrast en de wedstrijd naar zich toe trekt.
Hoe groot deze kansen zijn, kunnen we inschatten met data uit de voorgaande seizoenen. Wat gebeurde er de vorige keren dat er een ExpGD van +1.2 en omstreken werd voorspeld? Op deze manier kunnen de odds berekend worden. Voor de topper PSV – Feyenoord voorspelt het model een ExpGD van liefst +1.97, dus in het voordeel van PSV. Op basis van historische gegevens kunnen de volgende odds worden berekend.
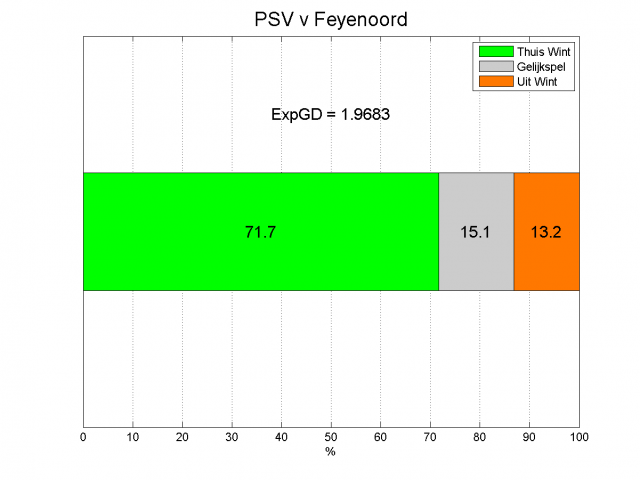
Voorgaande wedstrijden met een ExpGD van om en nabij +1.97 werden dus in 75.5% van de gevallen gewonnen door de thuisploeg. In de media wordt PSV bijna in een underdog-rol gedrukt, maar volgens het Pi-rating systeem hoeft de regerend kampioen weinig te vrezen.
Verbeterpunten
Toch zit hier nog een verbeterpunt in het model; de media zeggen immers niet voor niets dat de wedstrijd meer gelijk op zal gaan dan figuur 4 doet vermoeden. Feyenoord heeft deze zomer een flinke kwaliteitsinjectie gehad, terwijl PSV juist belangrijke spelers kwijt is geraakt. De Pi-rating houdt hier geen rekening mee en borduurt gewoon voort op de laatste wedstrijden van het vorige seizoen. Een mogelijke maatregel om hier rekening mee te houden is door in de eerste wedstrijden van het seizoen de leercurve van het model te verhogen, zodat een nieuw resultaat een grotere invloed heeft op de Pi-rating. Dit heeft dan wel weer als gevolg dat geluk een grotere rol kan gaan spelen.
Ook de Pi-ratings van promovendi vormen nog een knelpunt in het model. Als komend seizoen pak ‘m beet Sparta zou promoveren naar de Eredivisie, zouden ze beginnen met een Pi-rating van 0. Dit zou zeker in de eerste speelrondes tot grote fouten in de voorspellingen van wedstrijden van Sparta kunnen leiden, aangezien Sparta (waarschijnlijk) slechter is dan de gemiddelde eredivisionist. Promovendi die al in het systeem staan, krijgen hun laatst getaxeerde Pi-rating als beginpunt. Ook dit is niet ideaal; de kans is groot dat de teams zodanig zijn gewijzigd dat de Pi-rating niet meer accuraat is.
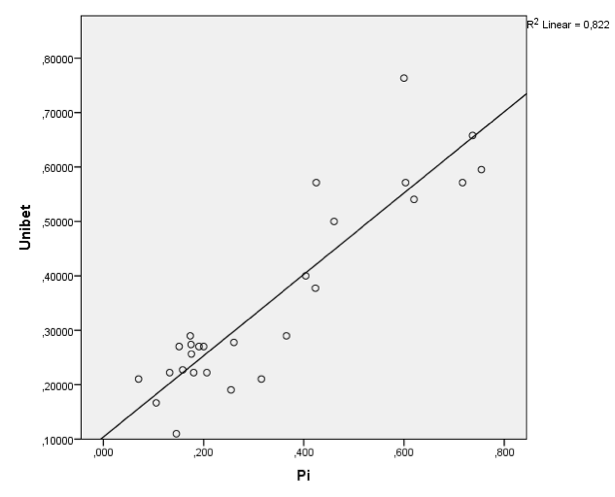
Deze en andere verbeterpunten die ongetwijfeld nog boven water zullen komen, zullen worden onderzocht en hopelijk ook daadwerkelijk verbeterd. Toch is de eerste indruk van het model goed. Voor de komende speelronde is er een sterke en significante correlatie (R2 = 0,822) tussen dit model en dat van Unibet (zie figuur 5), wat betekent dat er een sterk verband is tussen de twee modellen. Dus zelfs nu het model nog in de kinderschoenen staat en de Pi-ratings van de promovendi nog niet gestabiliseerd zijn, zijn de voorspellingen al redelijk accuraat.
En om nog even terug te komen op de miljoenen die je zou kunnen gaan verdienen met dit model, dat gaat als volgt: de bedenkers van het model berekenden de kansen en vergeleken die met een populaire gokwebsite. Voor elke wedstrijd werd gekeken waar het grootste verschil lag in het voordeel van het model, en daar werd een bet van één pond op geplaatst. Dit kan echter ook betekenen dat er een bet geplaatst wordt op wat een kleine kans heeft, zolang die kans maar groter is dan de kans die het wedskantoor hanteert. Mede daardoor werd er over vijf seizoenen netto welgeteld £57,62 verdiend. Bepaald geen goudmijn dus, maar wél beter dan het model van een populair wedkantoor.

































Er zijn reacties op dit artikel
Laat reacties zien Hide commentsErg leuk artikel! Maar ik heb nog een vraag, welke (statsitische) methode wordt er gebruikt om van expGD tot kansen te komen?
Beste Dirk,
Bedankt voor het compliment! De kansen worden berekend door de historie te bekijken. Aan alle wedstrijden sinds het seizoen 2010/11 werd een ExpGD toegekend. Bij een nieuwe wedstrijd krijg ik een ExpGD en kijk ik naar minimaal 50 wedstrijden uit het verleden die een vergelijkbare ExpGD hadden. Op basis van de uitkomsten van die wedstrijden worden de kansen op winst, gelijkspel en verlies berekend.
Dank voor de interesse!
Hi Dirk,
Bedankt voor het interessante artikel. Ik zou deze PI rating graag zelf willen toepassen. Heb je meer info hierover?
“Mede daardoor werd er over vijf seizoenen netto welgeteld £57,62 verdiend. Bepaald geen goudmijn dus, maar wél beter dan het model van een populair wedkantoor.”
Inderdaad bepaald geen goudmijn, maar als je het mij vraagt niet beter dan het model van het wedkantoor. De quotering die je daar ziet wordt namelijk niet alleen gegenereerd op basis van de berekende kansen. Ook inzetten van andere gebruikers en quoteringen van andere wedkantoren worden in ogenschouw genomen.
Een groot gebrek aan dit model vind ik dat dat de percentages voor aanpassen statisch zijn. Voor hen die het model niet kennen: de gecorrigeerde afwijking op je verwachting wordt op basis van een vast percentage gecombineerd met je vorige PI-rating. Een tweede percentage dat daar overheen gaat zorgt ervoor dat je uit-rating ook wordt bijgesteld wanneer je thuis hebt gespeeld en vice versa. De uitvinder van het model zoekt in zijn dataset naar de beste combinatie van aanpassingspercentages en past die overal toe (3,5% met daarvan 70% voor de tweede rating).
Ik heb het model toegepast op de eredivisie van 1990 – 2015, waarbij ik de return on investment voor seizoen 2015-2016 heb geprobeerd te bepalen. Mijn kantelpunt voor het correctiepercentage kwam uit op 0,00004 procent. Oftewel. als je nagenoeg niet corrigeert op de begindata (Waarbij de PI-rating 0 is), krijg je de minste afwijking op je voorspellingen. Alle verwachte scores liggen dan echter gebundeld op 2-0 voor de thuisploeg, 2-0 voor de uitploeg, of 0-0. Kortom, weinig voorspellend vermogen. Wanneer ik het model doorreken voor 2015 – 2016 kom ik bij een inleg van 306 euro uit op een return van 297 euro (oftewel, 9 euro verlies)
En als je het artikel hebt gelezen, zie je dat in twee van de vijf seizoenen, er verlies is gemaakt van zo’n 30 tot 40 pond. uit 1800 wedstrijden heeft hij uiteindelijk 57 pond winst kunnen verkrijgen. Dat is zo’n 3% rendement. Tel daar de 5% marge van de bookmaker bij op, dan kom je op 8% beter dan de gemiddelde speler (lees: gokker). Had hij maar over 4 seizoenen gerapporteerd (twee positieve en twee negatieve), dan was de winst mogelijk net boven 0 geweest. Maar had dat dubbeltje niet net zo goed de andere kant op kunnen vallen?
In het bouwen van mijn eigen model heb ik de leerpunten van de PI-rating meegenomen, maar heb losgelaten van de PI-rating en me gefocust op het aantal verwachte doelpunten voor de wedstrijd. Om het aantal doelpunten te corrigeren heb ik niet het grondlogaritme van het verschil gedeeld door een constante gedaan, maar ben ik zo vrij geweest om de wortel te trekken uit de afwijking. Dit leidt bijna tot dezelfde correctie en beiden zijn wat mij betreft arbitrair en suboptimaal, dus daar zit het verschil niet in. Voordat ik deze wortel trek, probeer ik echter lerend vermogen toe te passen door bij een thuiswedstrijd de gemiddelde afwijking van de laatste 5 thuis wedstrijden (en die van de laatste 5 uitwedstrijden voor een deel) hierbij op te tellen. Oftewel: zat ik de laatste wedstrijden gemiddeld steeds te positief te voorspellen, dan moet mijn rating hiervoor sterker bij worden gesteld dan de meest recente afwijking doet vermoeden.
Vertrekpunt van het aantal doelpunten in thuiswedstrijden en uitwedstrijden is het gemiddelde doelpuntenverschil van alle wedstrijden sinds 1990. Zo hoeft dit niet vanaf 0 op te worden gebouwd en verwacht ik iets zuiverdere data (anders vallen veel wedstrijden van het begin in het kwadrant rond de 0). – misschien valt hier nog een goede case uit te halen voor voorspellen van de correcte score…
Uiteindelijk is de grootste afwijking op dit model wat mij betreft het gebrek aan actualiteit. Een geschorste of geblesseerde sterspeler komt pas na een aantal wedstrijden terug in de ratings. Aankopen in het nieuwe seizoen, een nieuwe trainer, een spits die het ineens op z’n heupen krijgt, een speler die op scherp staat, Europees voetbal in de benen, de huidige competitiestand, eerder onderling resultaat (Ajax vs Utrecht), de scheidsrechter, de mate waarin een speler/coach in de media is geweest, interlandverplichtingen, het aantal wedstrijden in de afgelopen periode, de kwaliteit van de bank, uitslagen van de concurrentie, het weer, etc. kunnen allen tweaks aanbrengen in het model.
Kortom, de denkwijze van het PI-model is een mooie basis voor verdere analyse, maar als je er echt geld mee wilt verdienen, zul je toch een stuk verder moeten gaan dan dit.