Netwerk theorie wordt al een aantal jaren gebruikt om voetbalwedstrijden te analyseren, met als resultaat de opkomst van de ‘pass map’. De pass map geeft de meest belangrijke passverbindingen weer, alsmede de passintensiteit tussen spelers en (tot op heden) ook een spelers gemiddelde passpositie. In samenwerking met Piet Cremers (toenmalig Performance Coach Analysis bij NAC Breda), en aan de hand van Jan Mullenberg’s post over de zin en onzin van pass maps, heb ik een nieuwe pass map variant ontwikkeld waarbij gebruikt wordt gemaakt van clusteranalyse om zo spelersposities beter weer te kunnen geven.
Eerste Pass Maps
In 2012 lieten Peña & Touchette zien dat het mogelijk is om aan de hand van netwerk theorie metrics zoals PageRank, Closeness and Betweenness belangrijke spelers te identificeren binnen een pass netwerk. Buiten deze metrics lieten zij ook een visuele representatie zien van zo’n pass netwerk (Figuur 1).
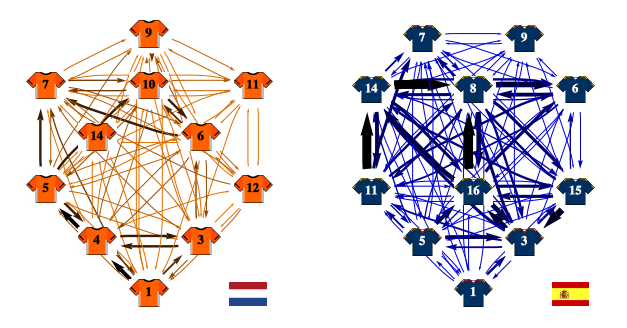
Ondanks dat deze figuren een redelijk helder beeld geven van de meest gebruikte passlijnen tussen spelers, zijn de spelerposities vastgezet op basis van de op papier bestaande formatie.
Pass maps van 11tegen11
Een aantal jaar later zijn deze pass maps geëvolueerd tot de pass maps zoals gemaakt door 11tegen11 (zie Figuur 2). Ondanks dat deze pass maps al weer een betere weergave zijn van de werkelijke locatie van de spelers binnen het netwerk hebben ook deze pass maps nog een aantal fundamentele kwalen die het lastig maken om ze te interpreteren.
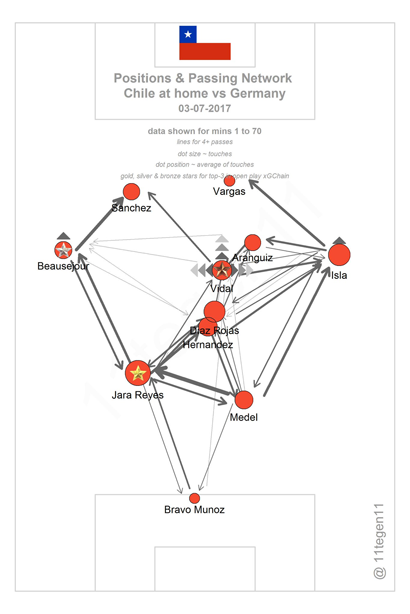
Ik zal in deze post niet verder ingaan op deze kwalen, aangezien deze al aardig zijn doorgelicht door Jan Mullenberg in zijn artikel De Zin en Onzin van de Passmap.
Kort gezegd zijn de belangrijkste problemen dat de richting van de pass zoals aangegeven door de pijlen niet de ware passrichting/gemiddelde passrichting van de speller in kwestie is, en ten tweede dat de gemiddelde passpositie zoals weergegeven in Figuur 2 zeer onbetrouwbaar kan zijn, met name voor spelers die veel van positie wisselen.
Hierover zegt Jan Mullenberg het volgende:
“Denk hierbij aan buitenspelers die graag van flank ruilen. Zo vormen Cristiano Ronaldo en Gareth Bale bij Real Madrid een sportief duo dat wel eens van kant wisselt. Bale speelt dan tijdens de 90 minuten aan zowel de linker-als aan de rechterkant. Bij de berekening van de gemiddelde positie van Bale kom je in de breedte rond het midden van het veld uit, maar dat is dan een vertekening van zijn werkelijke situatie.”
Dit laatste probleem heb ik proberen aan te pakken in ‘Pass Map 2.0’.
Pass Map 2.0
Om het probleem van de gemiddelde pass locatie te omzeilen maak ik gebruik van een cluster analyse. Deze cluster analyse gebruikt de x- en y-coördinaten van de passes van iedere speler en bekijkt welke passes behoren tot dezelfde groep, of cluster. Zo is het redelijk eenvoudig om positie wisselingen te ondervangen.
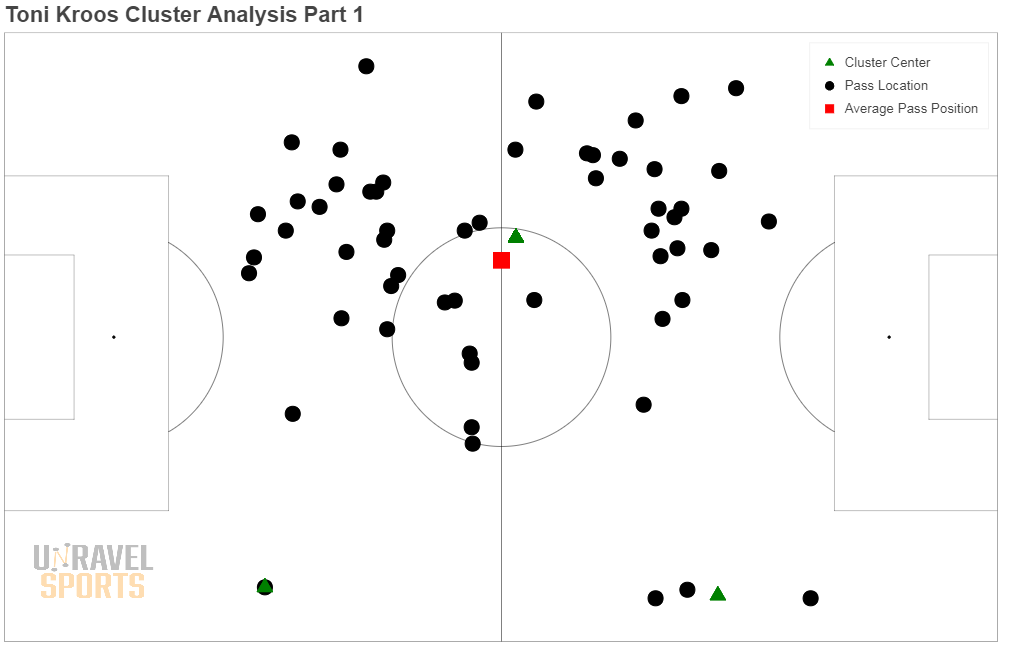
In Figuur 3 zijn alle passes van Toni Kroos weergegeven in een wedstrijd tegen FC Barcelona. Het algoritme identificeert drie clusters (de gemiddelde waarde per cluster is weergegeven met de driehoekjes).
Om de clusters beter te laten passen, verwijderen we clusters waarbij de clustergrootte gelijk is aan 1. Dit zijn duidelijke outliers (zie links onder in Figuur 3), waarna we het clusteralogritme nogmaals de clusters laten bepalen (Figuur 4). Vervolgens zien we heel duidelijk dat de passes van Kroos worden verdeeld over drie clusters; één kleine cluster op de rechter flank, één op zijn eigen helft en nog één richting de linkerflank.
Vervolgens gebruiken we de drie cluster gemiddelde (groene driehoekjes) om Toni Kroos z’n positie accurater weer te geven op de pass map dan wanneer we alleen het gemiddelde (rode vierkantje) hadden gebruikt.

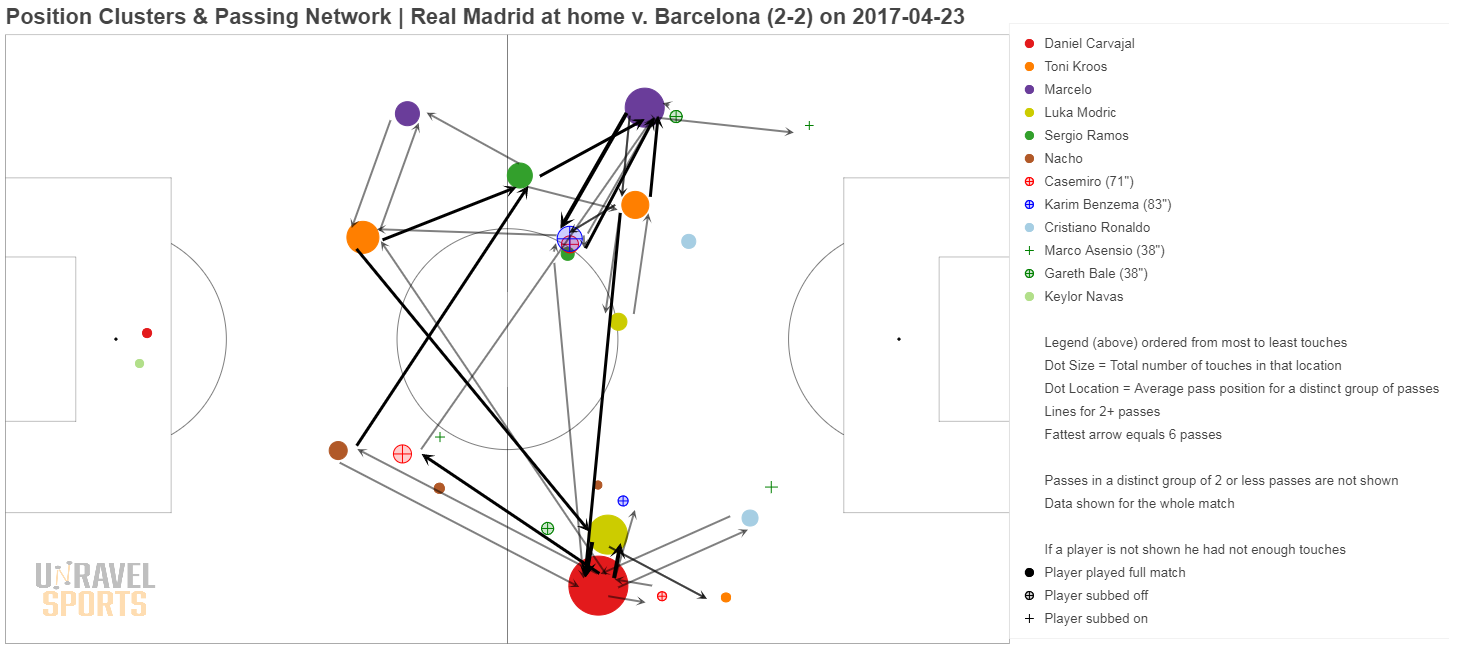
De nieuwe pass map voor Real Madrid tegen Barcelona zien we vervolgens in Figuur 5. We zien hier de cluster-gemiddelde van Toni Kroos weergegeven in het oranje, waarbij de grootte van de bollen wordt bepaald door het aantal passes. Ook zien we duidelijk dat voor zowel Ronaldo (licht blauw) als voor Bale (groene bol met kruis) twee punten op de pass map worden weergegeven, één op de linkerflank en één op de rechterflank (voor beide spelers).
Conclusie
Al met al kunnen we concluderen dat het toevoegen van meerdere ‘nodes’ per speler op basis van de geclusterde passlocaties een nog beter beeld van de werkelijkheid verschaft, zonder al te veel te verliezen aan leesbaarheid.
Ondanks dit blijft er natuurlijk nog één belangrijk punt van Jan Mullenberg over. Namelijk dat de pijlen niet de juist pass richting aangeven, omdat de aangeven spelerlocaties niet aangeven waar de bal wordt ontvangen, maar alleen vanwaar hij wordt gespeeld.
Dit probleem, is mijn inziens, echter alleen te verhelpen met behulp van interactieve tools waarbij de mogelijkheid wordt geboden om steeds één speler te selecteren. Van deze speler zien we dan de geclusterde gemiddelde passlocatie(s), en van alle andere spelers zien we dan de geclusterde gemiddelde ontvangst locaties.
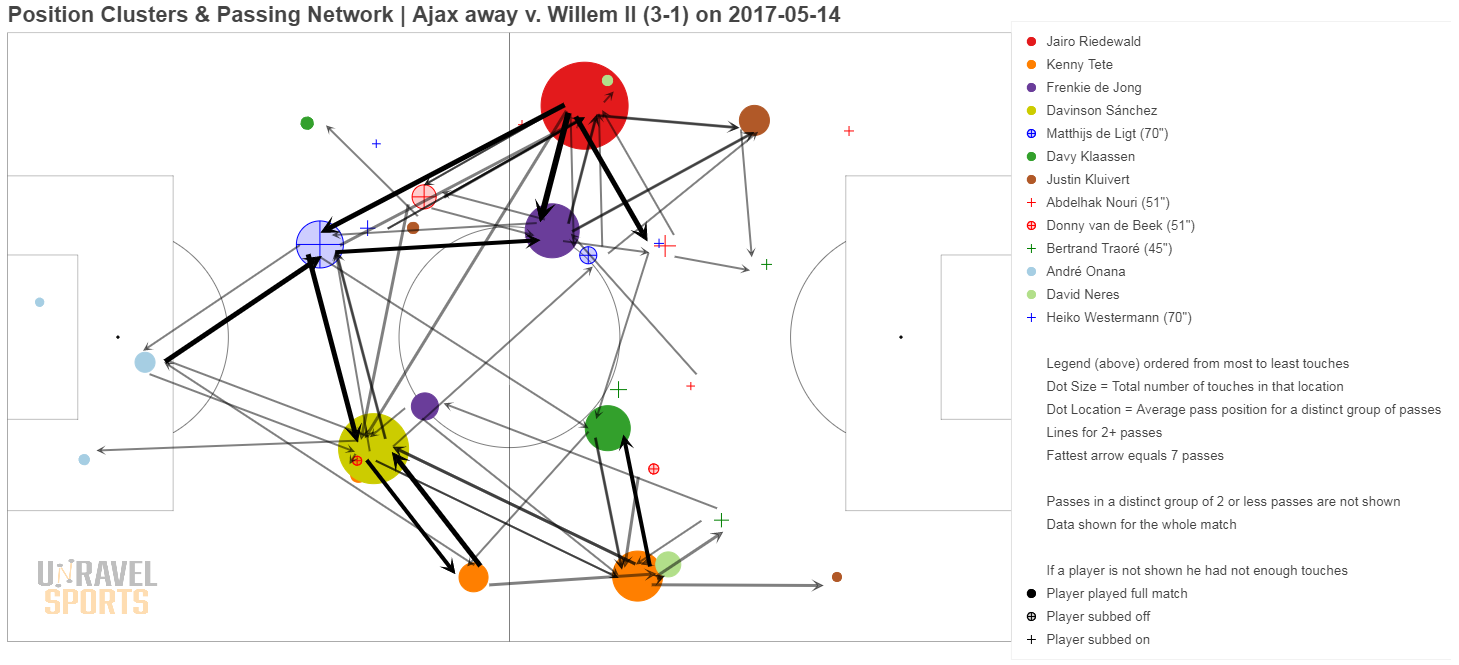
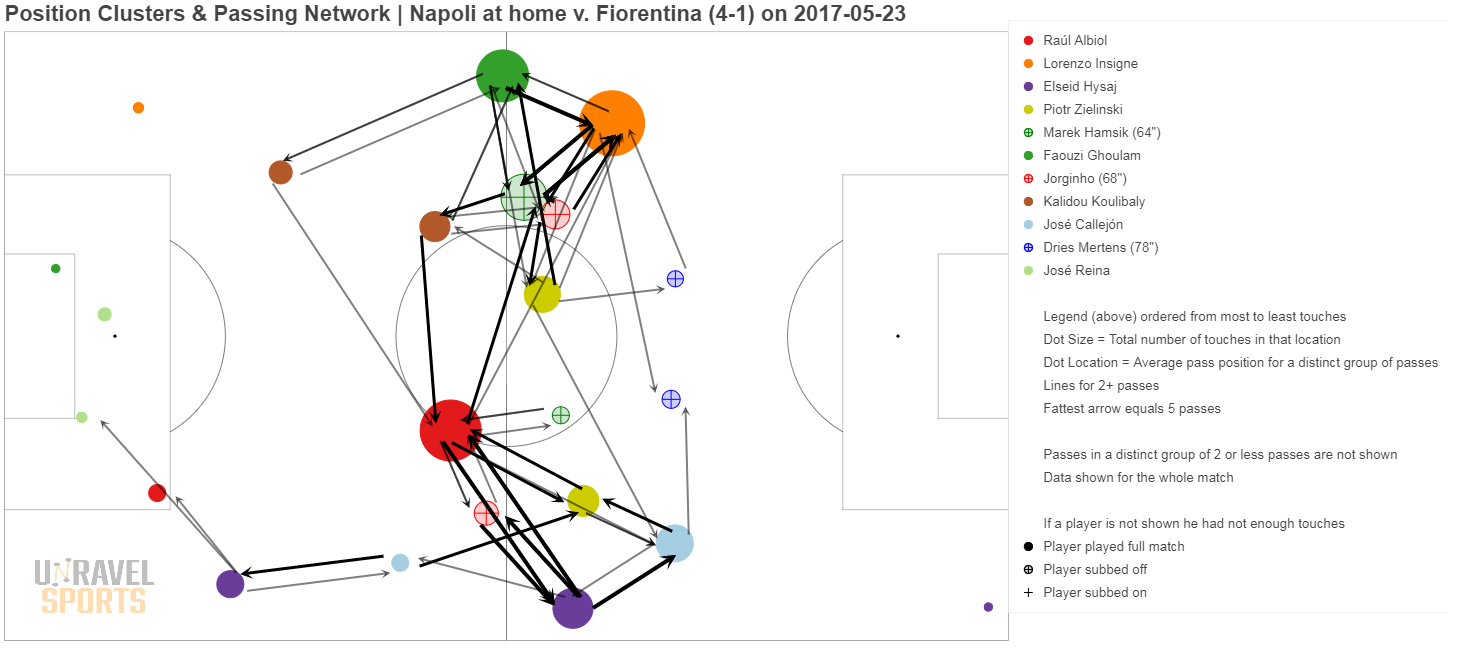
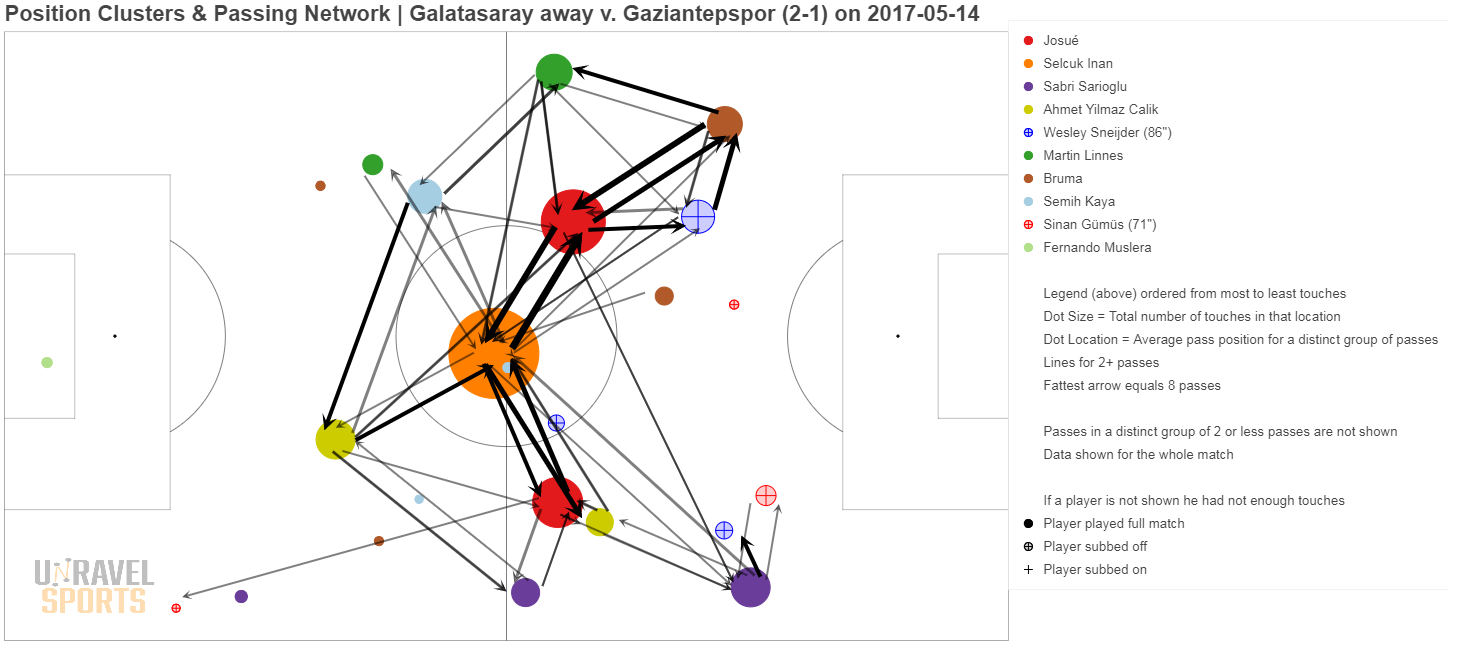
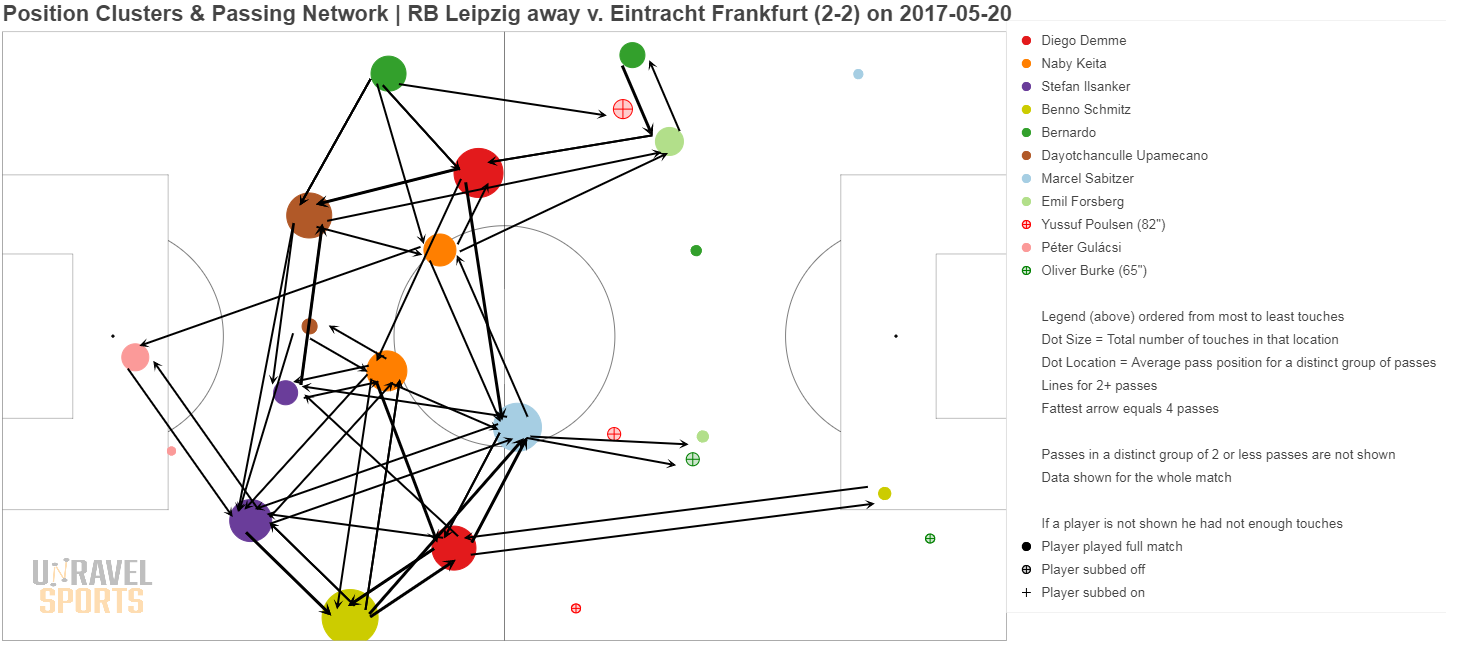
Bonus: hieronder nog wat andere voorbeelden

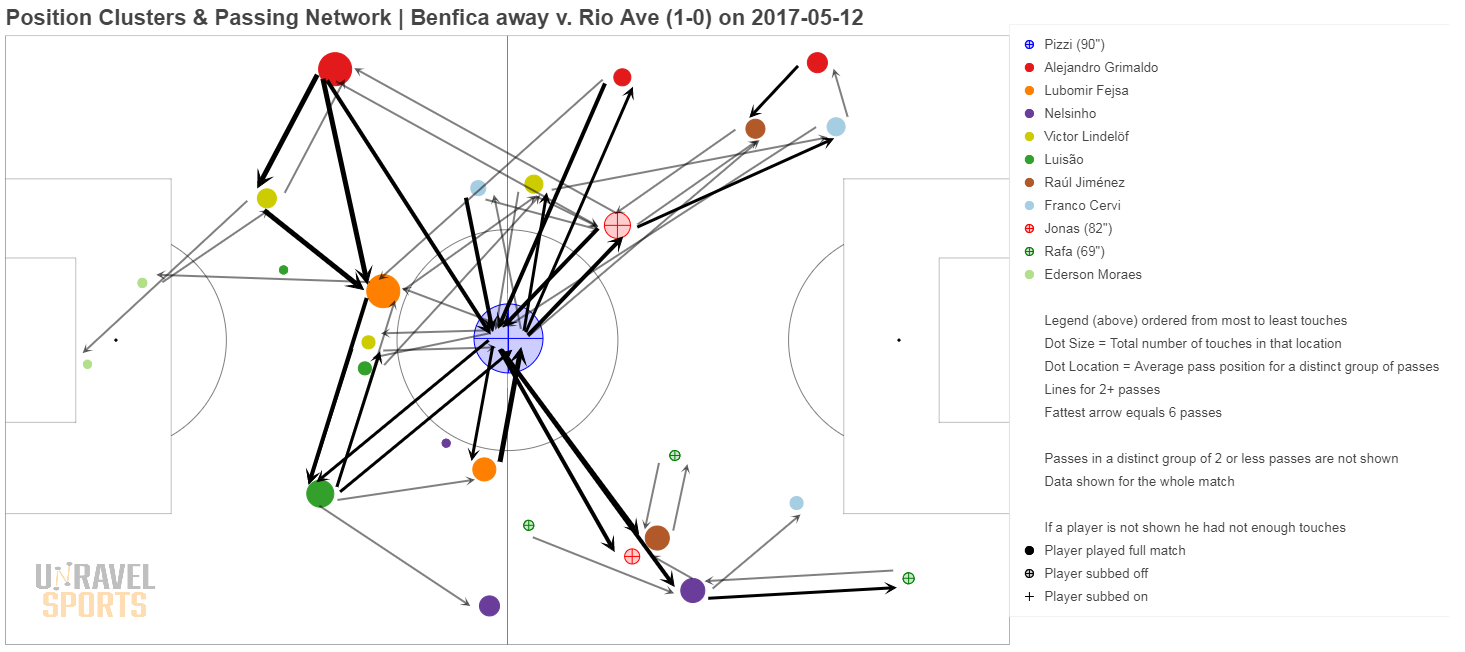
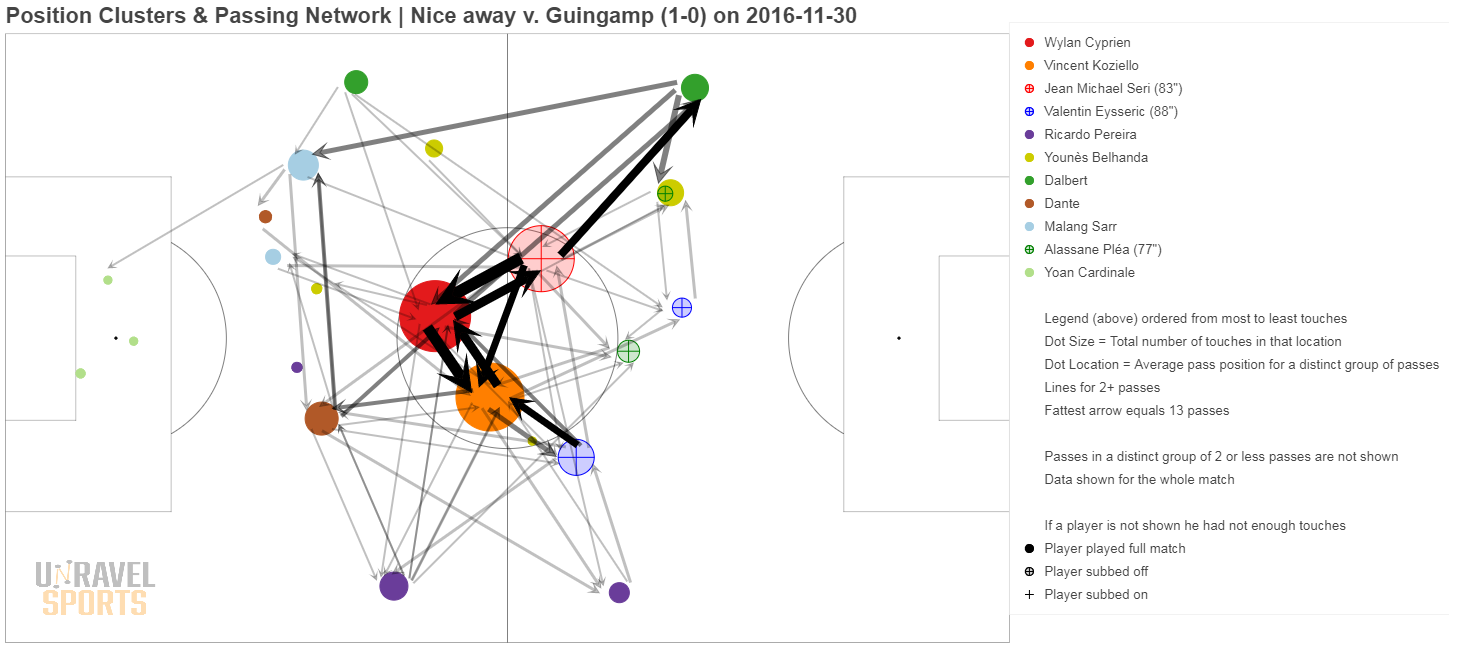
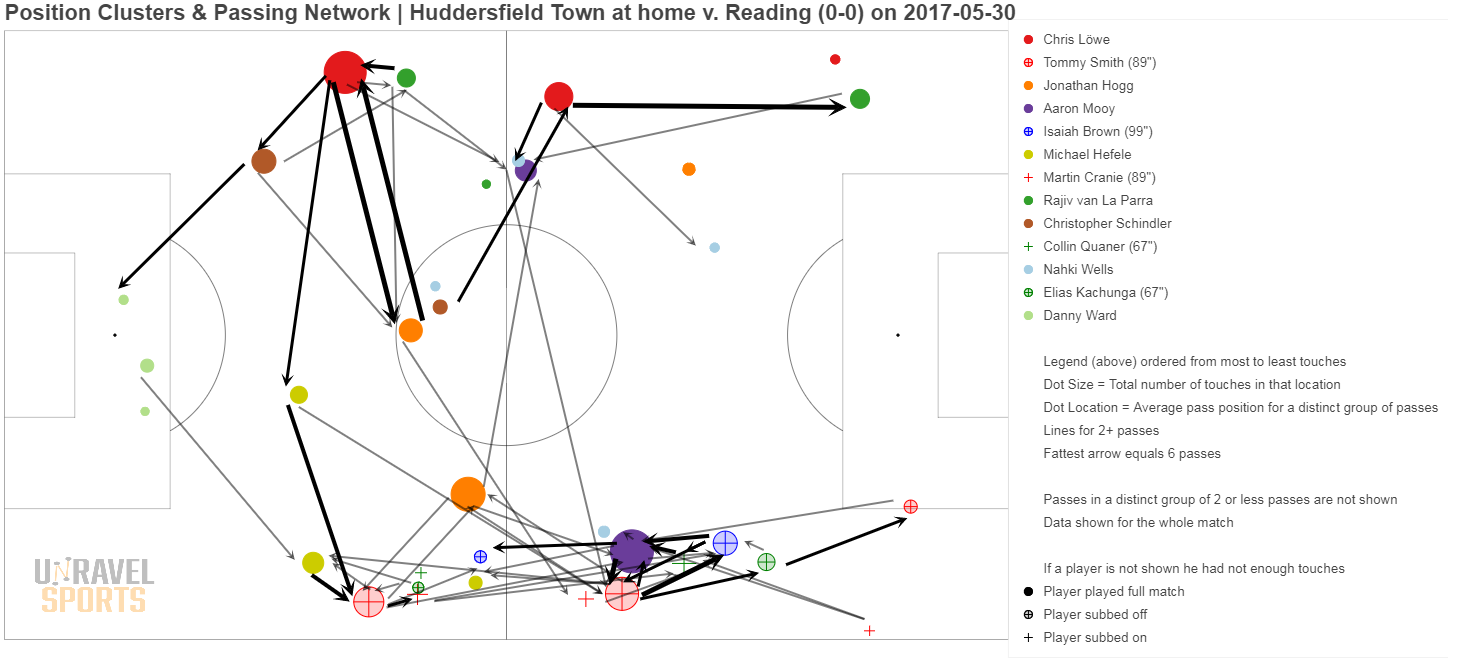






































Nog geen reacties
Geef je mening Cancel